AWS Cost Optimisation Checklist begins with practical FinOps tools and foundational strategies to help reduce cloud expenditure across storage, database and monitoring services.
Author: Ali Osman Başakıl – Senior Solution Architect, OBSS
LinkedIn: https://www.linkedin.com/in/basakil/
AWS entered our lives many years ago and made them a lot easier. It started with simple services, like object storage and virtual machines, then a lot of managed services are put in service. But these all come at a cost (pun intended), and with a little more attention and a bit of work, you can reduce a fair amount of your cloud bills. This article series intend to give you a checklist for quick and simple advices to do that, in an organized manner. I tried to be brief and concise, so there are hyperlinks to detailed documentation links and examples, wherever applicable.
“Cost optimisation checklist for AWS” comprises the last two parts of the three part FinOps series and contains five sections. First section, “Tools to observe your cloud expenditure” introduces AWS’s own tools that help you to understand your expenditure so that you can act on avoidable ones with the tools you learn in the following sections. Second section lists general items. Third section explains cost reduction tips on storage and db related services. Fourth section shows tips on compute related services. Finally, the last section tries to make you understand your network related costs and adds a summary part.
01 — Tools to observe your cloud expenditure:
This chapter is all about the “Inform” phase of FinOps. Premature optimisation is a trap to avoid, so we should better gather information.
🗹 Use Cost Explorer & Reports:
Cost explorer is the main resource to find where excess costs are occurring in your account. After you enable it, you can view current expenditures and forecasts, both using graphs and detailed reports.
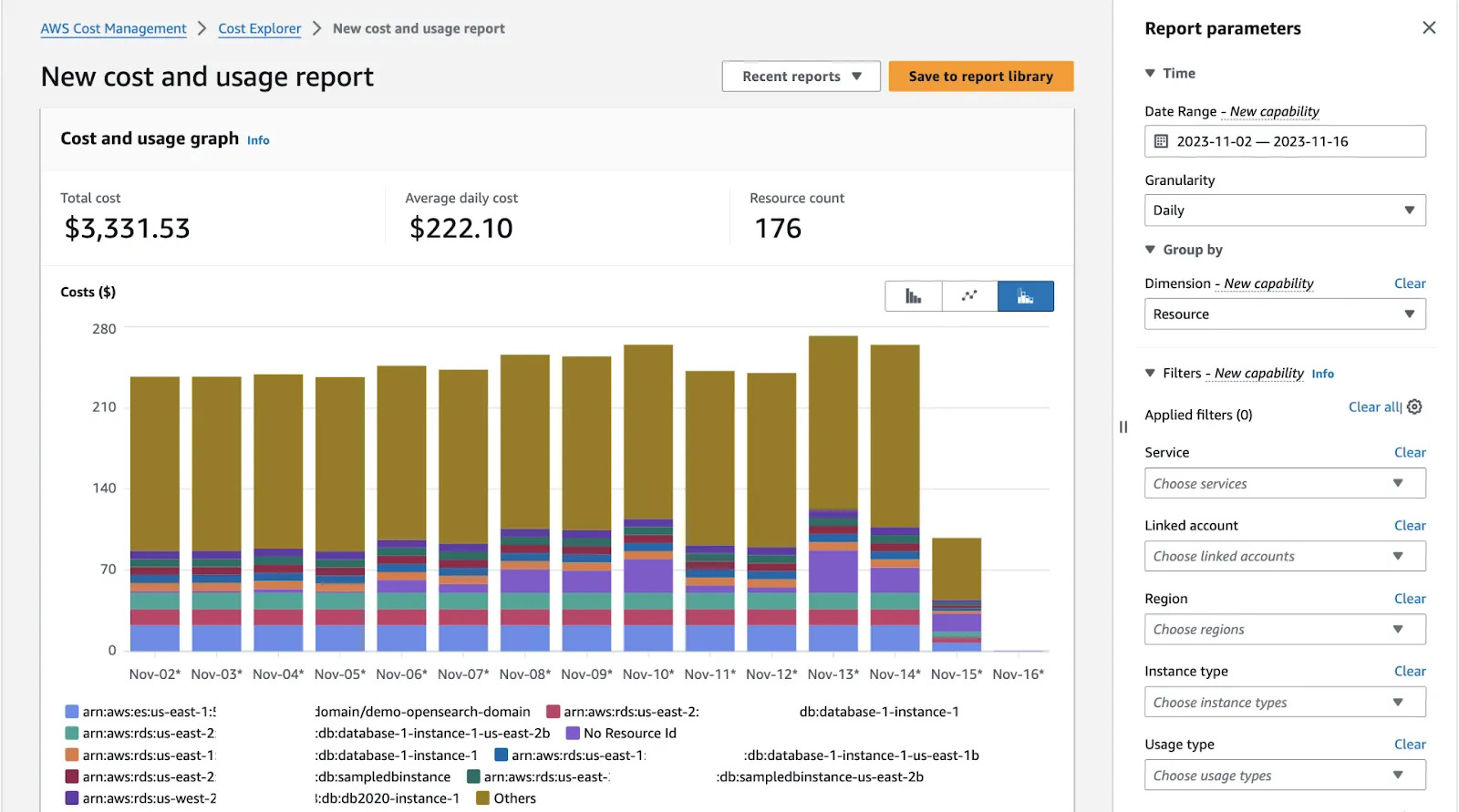
Ease: 3/5 : Dashboard style general reporting is easy to understand but you may have to dive deep into reports to make fine grained decisions.
Effect: 2/5: First few visits may reveal big gains but after applying other items (in this list), you will feel you don’t need that much any more.
🗹 Use Budget alarms:
You can add cost budgets (and alarms), which inform you if your current costs are above a set threshold. Budget alarms can also be used to track (and fire alarms for future) cost estimations, in addition to actual costs. Below image shows the steps to create cost bucgets, and in the subsequent steps, budget alarms.
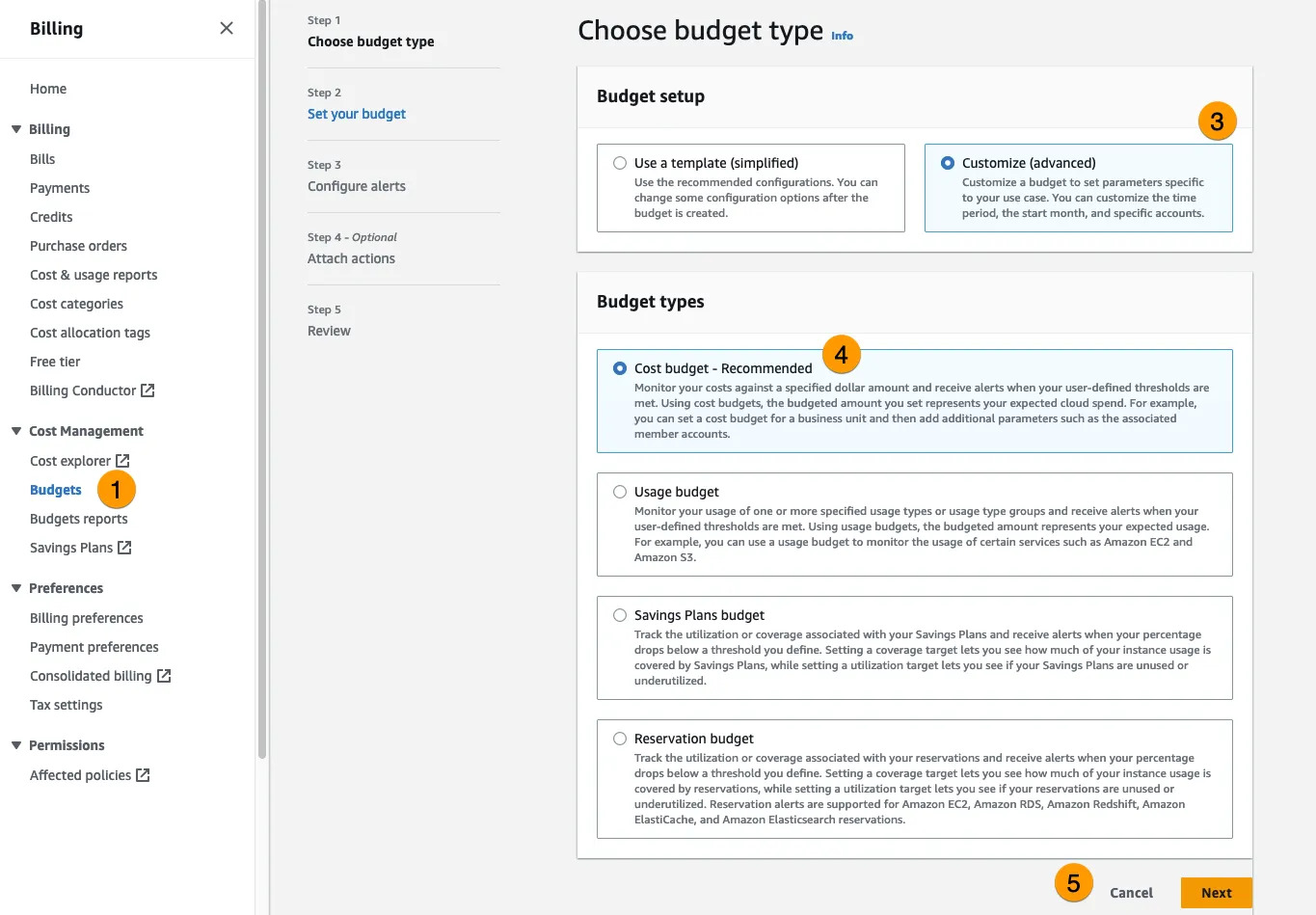
Ease: 4/5: It is very easy to set a few budget alarms
Effect: 1/5: Alarms do not cause/show a direct gain but can be anchor to your spending, if you’ve mistakenly enabled something.
🗹 Use (cost allocation) tags
Adding (cost related) tags to resources makes it easy to group and track related costs.You can then use cost explorer and see your reports grouped by those tags.
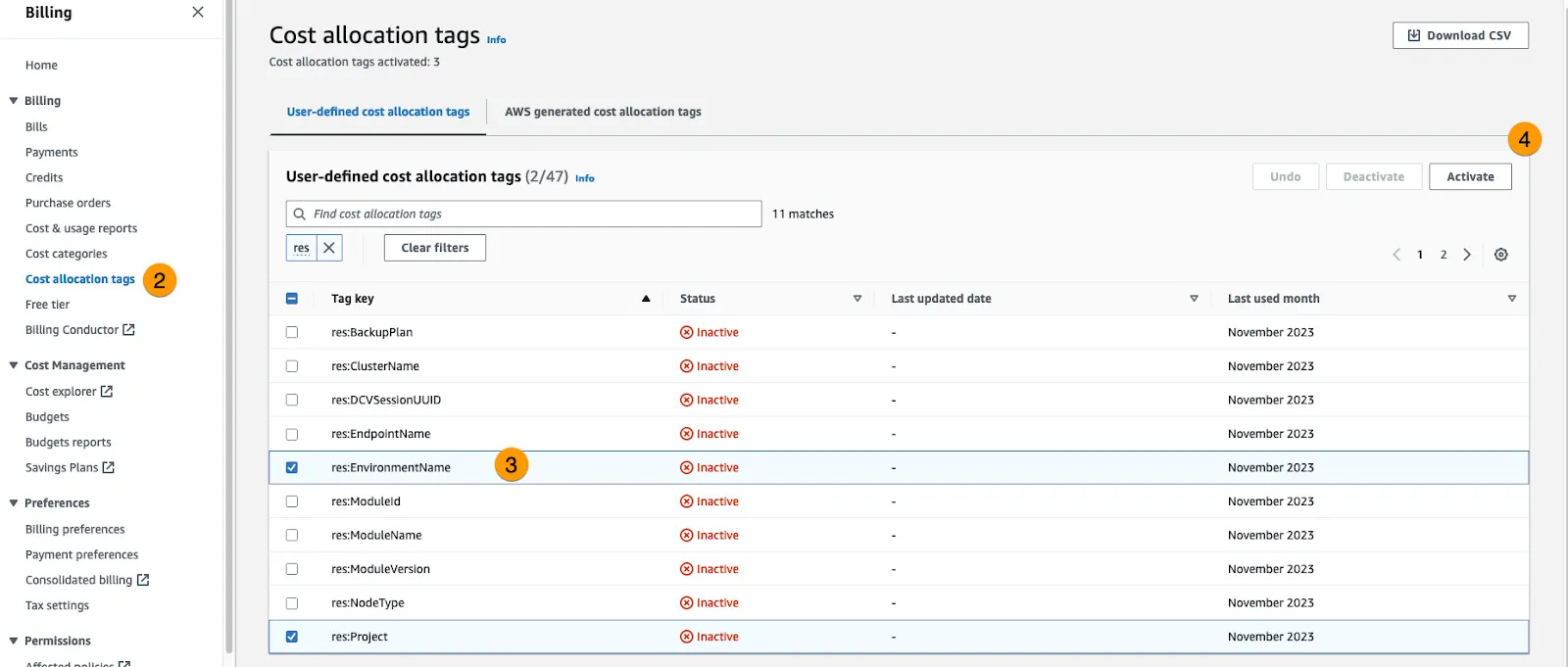
Ease: 2/5: It is not that easy to set rulesets and usage restrictions for cost allocation tags.
Effect: 2/5: This does not directly reduce your spendings but gives a better view of them.
🗹 Use (Cost section of) Trusted Advisor:
Trusted Advisor gives advices for a handful of sections and cost section is one of these. It can be an easy visit, before you dive into more advanced tools.
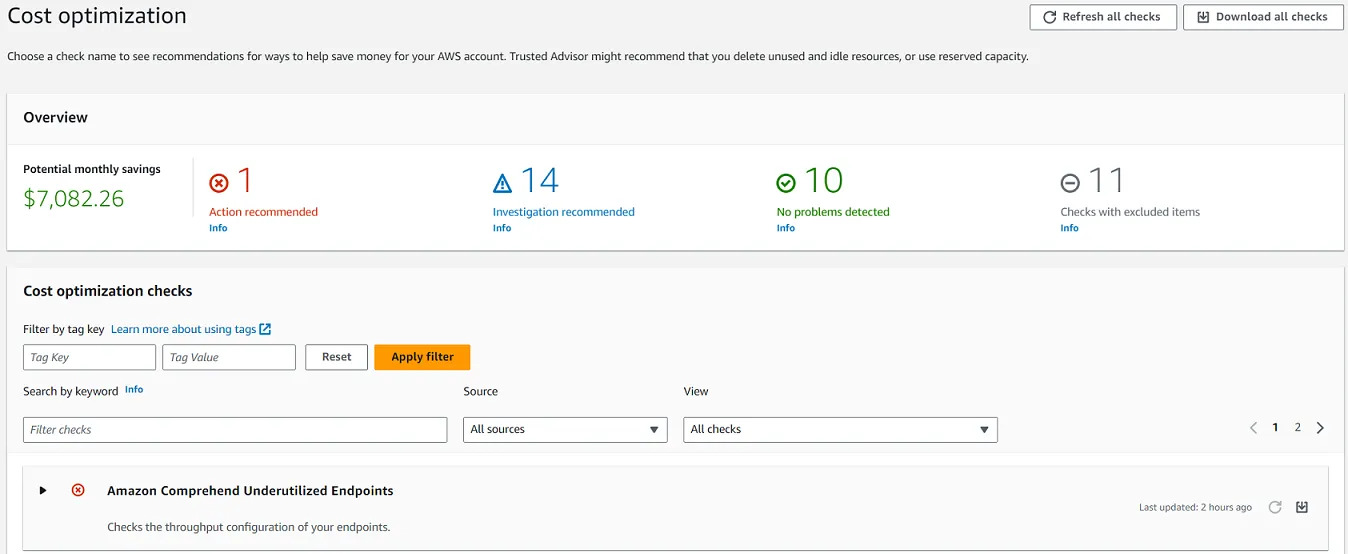
Ease: 5/5: It is very easy to enable it.
Effect: 3/5: It can actually give pretty good advices.
🗹 Watch metrics & logs:
CloudWatch Metrics give information about resource utilization and can direct you to unexpected resource usage. Application logs and access logs may give information when unexpected costs occur. As an example; your load balancer may be under complicated DDoS or bot attack and you can detect this via tracing ELB access logs, ELB and compute metrics. You can even create metric or log alarms, if you see a pattern.
Ease: 1/5: Metrics and logs are readily available for some services but it can be hard to extract useful information out of them. It usually needs time and experience to do it efficiently.
Effect: 3/5: It can detect many areas where others fail.
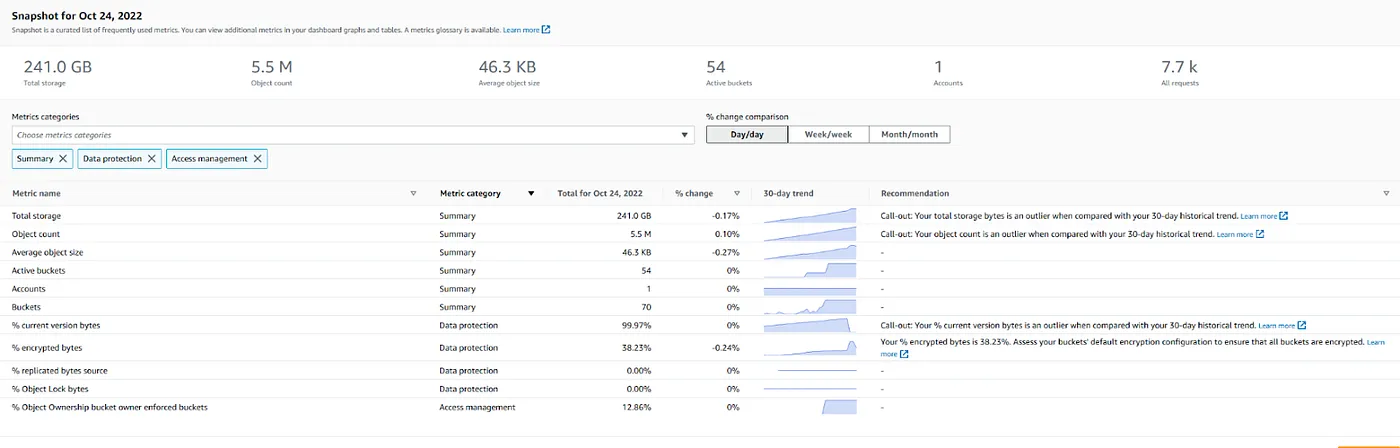
🗹 Use Storage Lens:
S3 Storage Lens can be used to get an overview of S3 usage, current and historical.
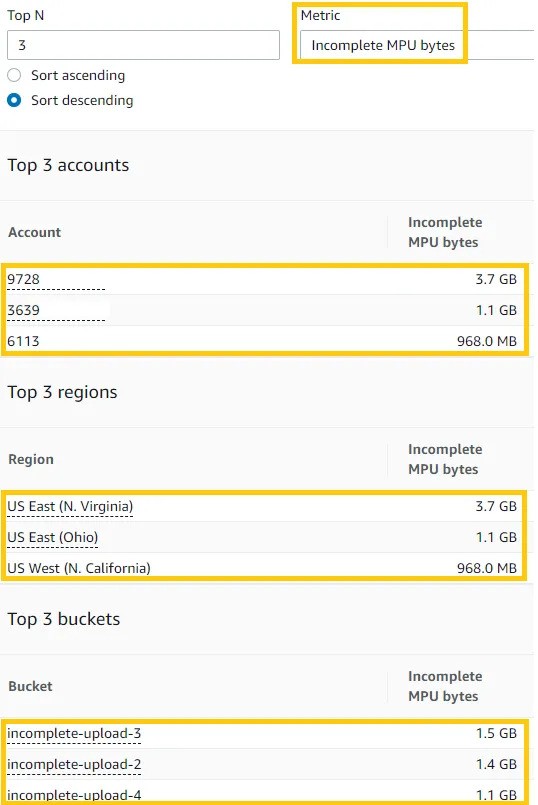
Interrupted multipart uploads can cause unnecessary S3 storage costs. You can scroll down to “Top N overview” in the storage lens dashboard window and find “Incomplete MPU Bytes” which depicts the amount of incomplete multipart uploads, as bytes. But there is a better solution to this: You can configure an S3 bucket lifecycle policy to remove old incomplete MPUs automatically.
Ease: 3/5: It has a useful dashboard but going into details can be tiresome.
Effect: 2/5: It is service specific and has a limited focus.
02 — General
🗹 Use AWS Organisations:
In addition to making it easy to manage and organize your accounts and resources, using AWS Organizations can also have a direct effect of reduced costs, for some resources. S3 is an example. The more objects you store in S3, your unit pricing drops, step by step.
Below shows sample steppings:
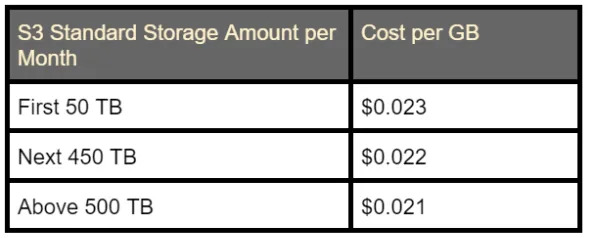
If you combine all (or most) of your accounts in AWS Organisations and utilize consolidated billing, AWS behaves all your resource usage and expenditures as if they are coming from a single account, so your costs hit reduced pricing steps earlier. Below is an example calculated for storing 100GB (on the average) in 10 accounts:
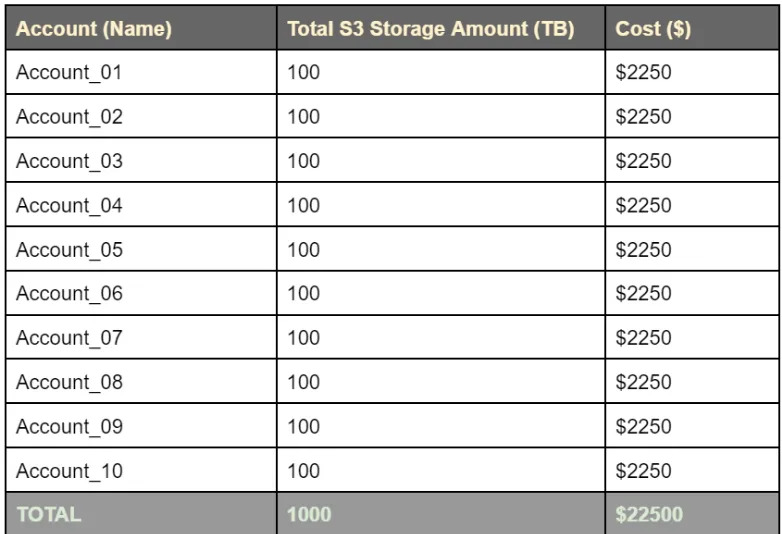
Total cost, without consolidated billing, is 50000*0.023 + 50000*0.022 = $2250 per account, so $22500 for 10 accounts.
If consolidated billing is used, it will be 50000*0.023+450000*0.022+500000*0.021 = $21550 for 10 accounts, which is $1000 lower than sans consolidated billing.
AWS Organisations have also other cost related benefits, such as sharing reserved instances and saving plans across accounts, so you may get more benefits from other items by enabling and setting up AWS Organisations.
Ease: 2/5: It’s main purpose is not about cost and It is may be difficult to setup, if you’ve not done before.
Effect: 1/5: Has a limited cost reduction rate.
🗹 Work with an AWS Partner:
AWS has a partnership program, with more than two thousand companies already enrolled in. If you work with an advanced or premium tier service partner, you will most probably be entitled to discounts, amount changing according to your use case. You can find a partner here.
Ease: 5/5: You won’t be doing much.
Effect: 2/5
03- Storage and DB
🗹 Use S3 storage classes and lifecycle policies:
S3 has different storage classes that have different storage costs and access costs. They are inversely related (classes having lower storage prices have higher access prices). Rarely accessed data can be moved to Glacier storage classes.
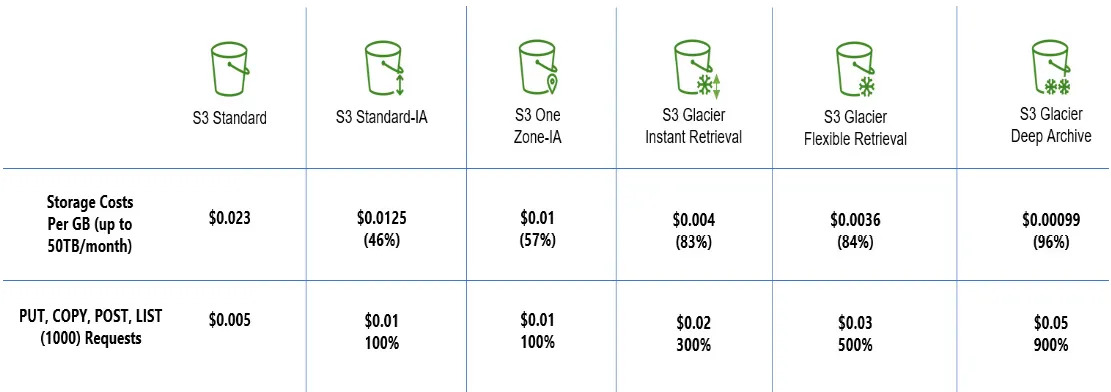
There is also a new class, called intelligent tiering, which automatically moves between tiers (except Glacier classes, afaik). It can also be used, if it seems tedious to observe and switch tiers. But in this case, S3 lifecycle policies can also be utilized:
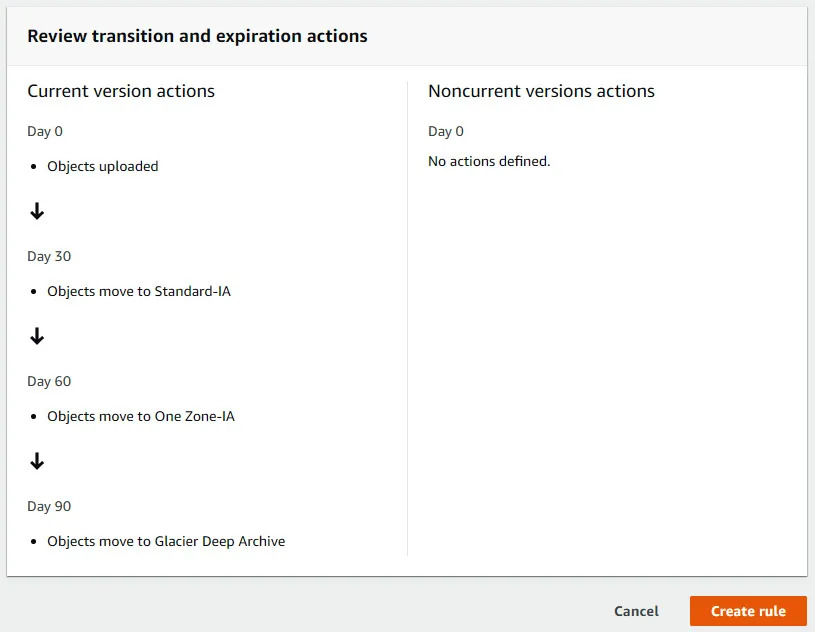
Note that, each tier switch, manual or by policy, costs around $0.01 for a thousand requests (objects).
Ease: 4/5: Setting up lifecycle policies is not that difficult. Intelligent tiering also automates some of the work..
Effect: 3/5: You can achieve quite a lot of gains if you are storing lots of large objects..
🗹 Use Reserved Instances for datastore services:
“Compute Savings Plan” is the preferred path to go for compute services in AWS but Reserved Instances is still the choice for RDS, OpenSearch and the services like (since there’s no compute savings option for them, yet). Keep in mind that, reserving intra-region instances has more advantages, like using them as stand-by replicas and being able to be more specific for instance types (since AZs will already be selected). It is also advised to enable auto-expand for all instances.
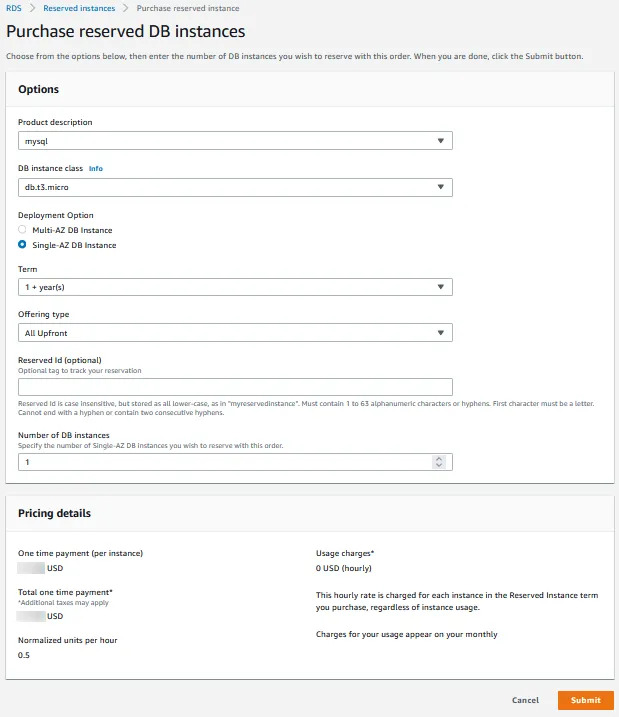
Ease: 3/5
Effect: 4/5: Reserved instances usually have high returns, especially with high utilization.
🗹 Use OpenSearch ultra-warm nodes:
In addition to using reserved instances for OpenSearch nodes, you can also enable ultra-warm storage (which utilize S3), wherever applicable. Note that ultra-warm nodes can only be used for read-only indexes.
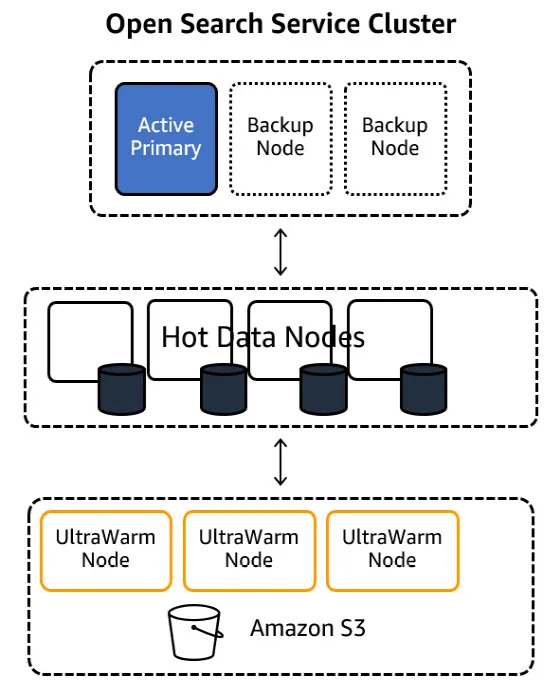
Ease: 2/5: Monitoring and weigthing the effectiveness may be difficult.
Effect: 2/5: Has limited use cases..
🗹 Use DynamoDB capacity modes and reserved capacity:
If you are using DynamoDB, you’ll already be using one of the capacity modes.Default is the on-demand mode.You can switch to provisioned capacity and provision read + write units after viewing ConsumedReadCapacityUnits and ConsumedWriteCapacityUnits DynamoDB metrics. A better way is to enable (provisioned capacity) autoscaling:
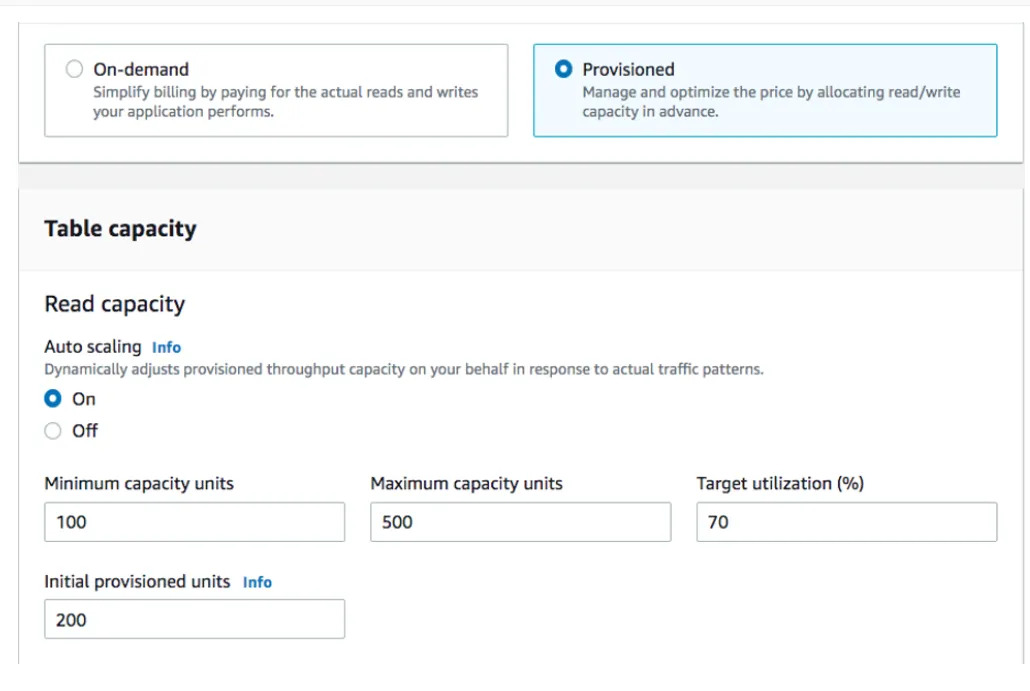
Below is an active monitoring of how auto-scaling works. If you define a larger target utilization, you pay less but you risk hitting the capacity on usage spikes (eg: check ~12 UTC at the graph):
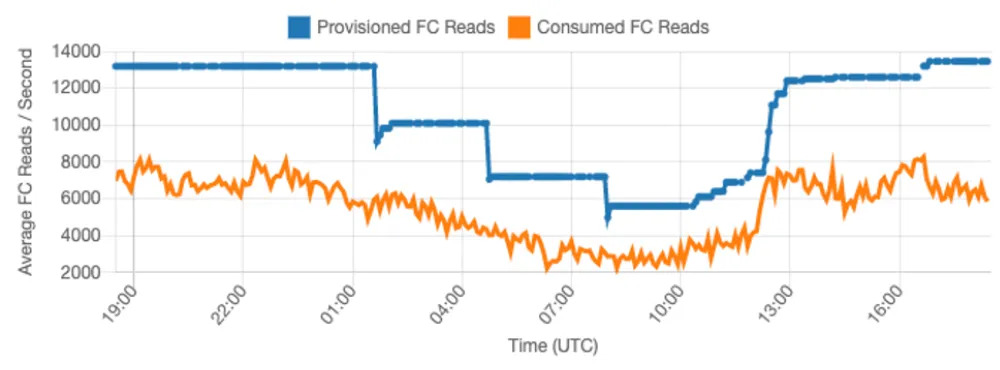
Ease: 4/5: Not that difficult to enable and monitor provisioned capacity, and auto scaling reduces the risks.
Effect: 3/5: Definitely provides some cost gains.
🗹 Use EBS Snapshot Archives and EBS Recycle Bin:
You will probably be storing EBS snapshots, if you are working with EC2 instances a lot, on production. It is one of the easiest methods of backing up instances and a way of creating golden AMIs.
These backups can be archieved in a region after a while (eg: 3 months) and sent to the requesting region(s) whenever required. EBS Recyle bin provides a way to send these archives to trash (eg: after a year), with an option to recover, for a limited time period. You can also define retention rules for archives and recycle bin, to automate these processes.
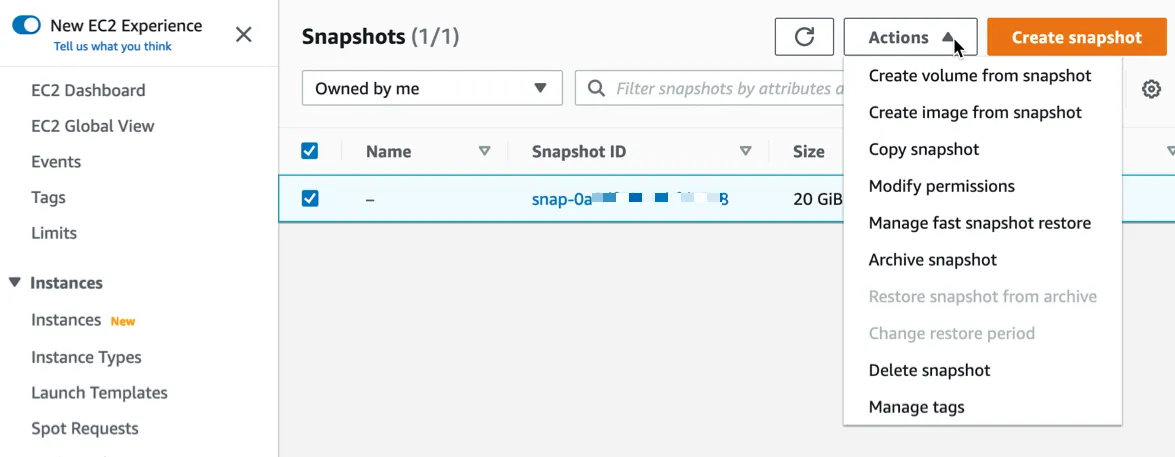
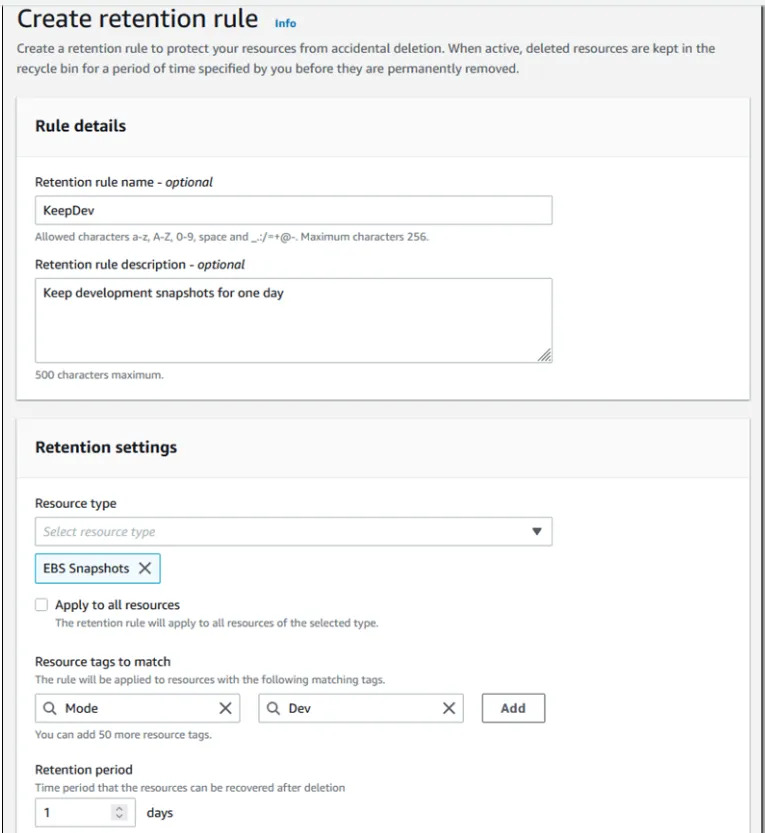
Ease: 4/5: Setting up rules and archives is easy.
Effect: 2/5: You can achieve a bit of gain, to an extend, if you are keeping a lot of images.
🗹 Use EFS storage classes:
EFS has storage classes, similar to S3. EFS also have intelligent tiering and lifecycle policies:
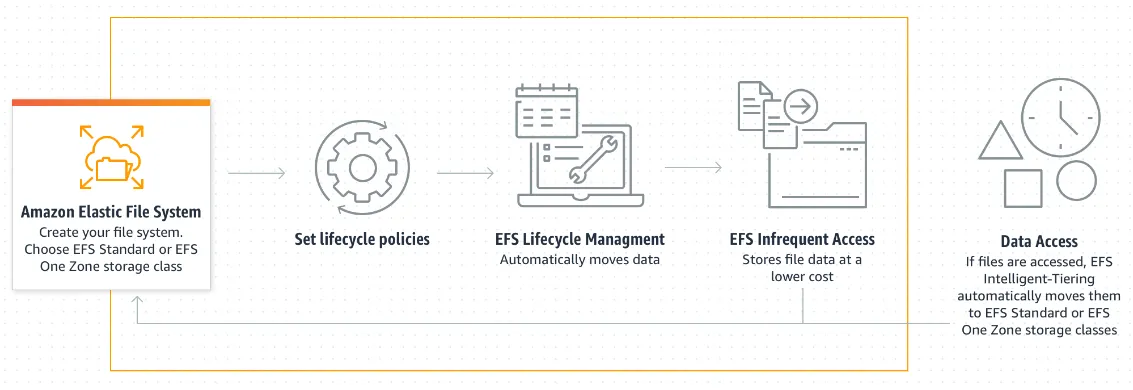
Ease: 4/5: Setting up lifecycle policies is not that difficult. Intelligent tiering also automates some of the work.
Effect: 2/5: You can achieve quite a lot of gains if you are storing lots of large objects but EFS is not as widespread as S3.
Note: This is the second part of a three part series. The first part is here, and the next part is here.