Son zamanlarda güçlü bir kültüre ve işlerin nasıl yapılacağına dair net tercihlere sahip bir kuruluş için bir mikro hizmet projesi üzerinde çalışıyoruz. Bu kuruluş monolitik bir geçmişten gelmesine rağmen, tatmin edici bir sonuç elde etmeyi başardık, hoş ve yapıcı bir iletişim kurduk ve bazı ilginç tasarım seçimleri yaptık. Çoğunlukla mikro hizmet mimarisinin teknik yönlerine odaklanacağım ve DDD ve DevOps konularından kaçınacağız:
Elimden gelen en iyi şekilde ödünleşmeleri açıklamaya çalışırken organizasyonun gizliliğine de saygı göstereceğim. Daha fazla uzatmadan, ele alacağımız konulara bir göz atalım:
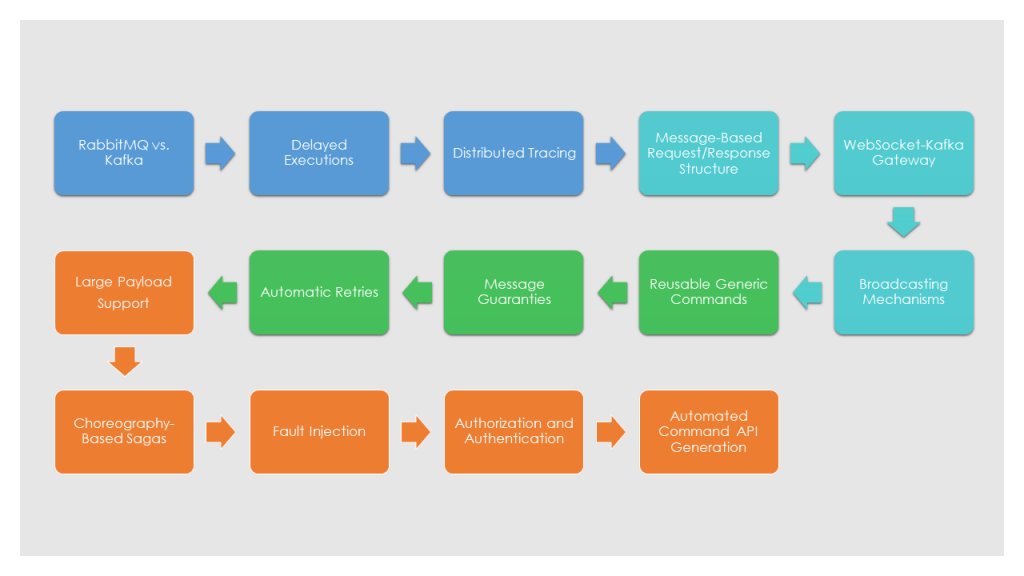
Bölüm 1: (this part)
- RabbitMQ vs. Kafka
- Gecikmeli Çalıştırmalar
- Distributed Tracing
- Mesaja Dayalı İstek/Yanıt Yapısı
- WebSocket-Kafka Geçidi
- Yayın Mekanizmaları
- Yeniden Kullanılabilir Genel Komutlar
- Mesaj Garantileri
- Otomatik Tekrar Denemeler (Sıralı ve Sırasız) ile Üssel Geri Dönüşler
- Büyük Yük Desteği
- Koreografi Tabanlı Sagos
- Hata Enjeksiyonu
- Yetkilendirme ve Kimlik Doğrulama
- Otomatik Komut API Üretimi
Çalıştığımız organizasyon, monolitik masaüstü uygulamalarından web tabanlı mikroservis uygulamalarına geçiş yapıyordu. Bu yüzden yeniden yapılandırmalar mevcut. Zaten çok uzun bir sıçrama olduğu için hedef kuleyi fazla yükseltmek istemedik. Bu nedenle yeni teknoloji ve araçların sayısını minimumda tutmaya karar verdik. Ayrıca, gereken dağıtık işlemlerin sayısını azaltmak için bazı servislerin biraz büyük olmasına izin verdik. Bununla birlikte, yine de 20'den fazla bireysel servise bakıyoruz (kopyalar olmadan), bu yüzden çözülmesi gereken birçok sorun var.
Many of our approaches/solutions to technical problems use or dictated by another. I will be going over them in an order that helps to explain our reasoning.
RabbitMQ vs. Kafka
Eğer event-driven bir uygulama geliştiriyorsanız, bir message-broker’a ihtiyacınız olacaktır. Muhtemelen en popüler iki tanesi RabbitMQ ve Kafka'dır.
İkisini karşılaştırırken, en yararlı ayrım, RabbitMQ'nun iten bir kuyruk, Kafka'nın ise tüketicilerin mesajları çekmesini bekleyen bir günlük olmasıdır. Bu zıtlık önemli mimari farklılıkları belirlerken, en yaygın senaryolar için her ikisi de benzer yetenekler sunar. Birçok makale bu iki sistemi detaylı bir şekilde karşılaştırmaktadır. Bu makalede olduğu gibi: (https://jack-vanlightly.com/blog/2017/12/4/rabbitmq-vs-kafka-part-1-messaging-topologies)
Bazı kullanım senaryolarımız, hizmetlerin belirli mesajları oluşturuldukları sırayla işlemesini gerektiriyor, bu nedenle message-ordering’e ihtiyacımız var. Ve performans hedeflerimiz, tercihen auto-scaling ile hizmetlerin yatay ölçeklendirilmesini gerektiriyor.
Her iki çerçeve de bu gereksinimleri ayrı ayrı oldukça iyi karşılar. Ancak, auto-scaling ile ve message-ordering’i birleştirdiğinizde, Kafka bir adım öne çıkıyor.
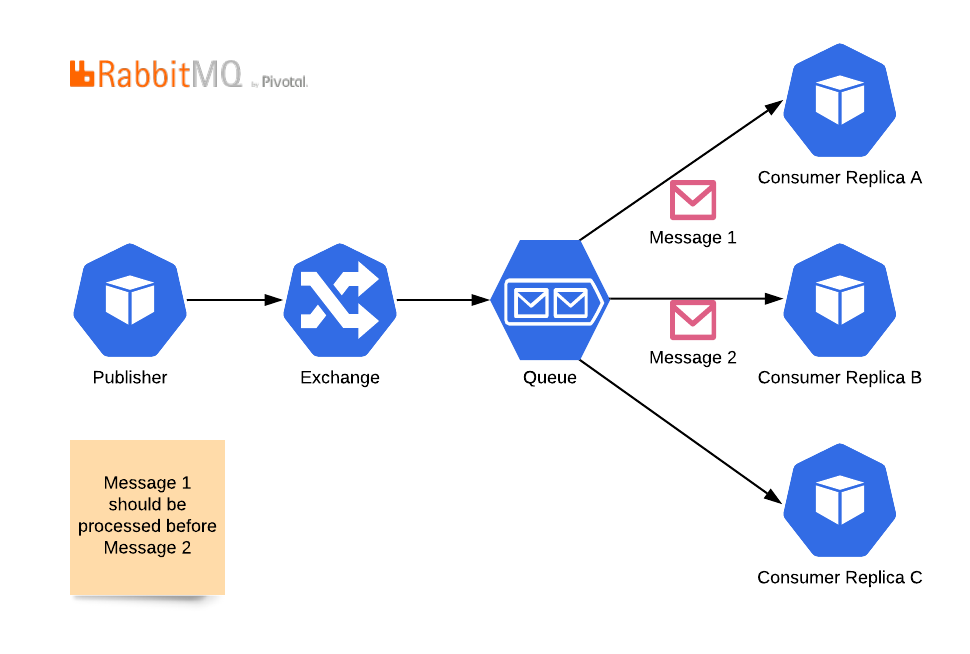
RabbitMQ'da mesajlar bir exchange'den geçer, bir kuyruğa düşer ve ardından bir mesajın yalnızca bir tüketiciye gidebileceği şekilde tüketicilere dağıtılır. Tüketicilerin replika sayısını artırmak çok kolaydır, ancak bu topolojide mesaj sıralamasını kaybedersiniz. Çünkü ikinci mesaj, birincisi tamamlanmadan önce işlenebilir.Kopyalar ve mesaj sıralamasını bir arada tutmak için şu topolojiyi kullanabilirsiniz:
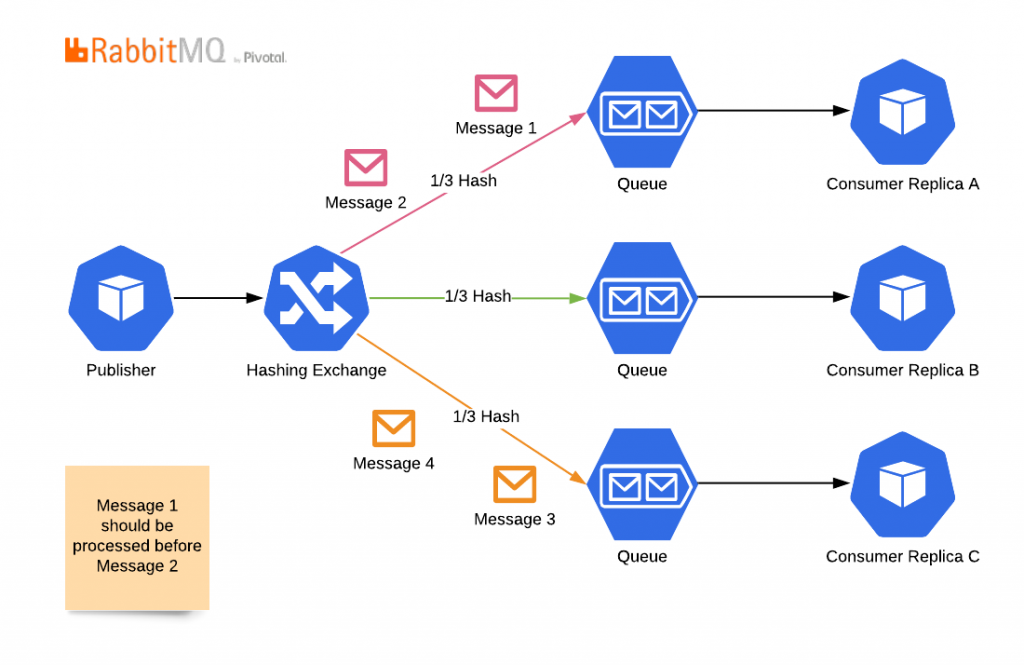
Ancak, bu topolojide otomatik ölçeklenmeyi kaybedersiniz. Hashing alanınızın izin verdiği kadar fazla kopya ekleyemezsiniz. Daha da önemlisi, hashing alanınızdan daha az kopya kullanamazsınız. Çünkü bu durumda, mesajlar bir kuyruğa gider ama hiçbir zaman tüketilmez.
Kısaca buradaki environment altındaki tanımlamalarımızı da özetleyecek olursak:
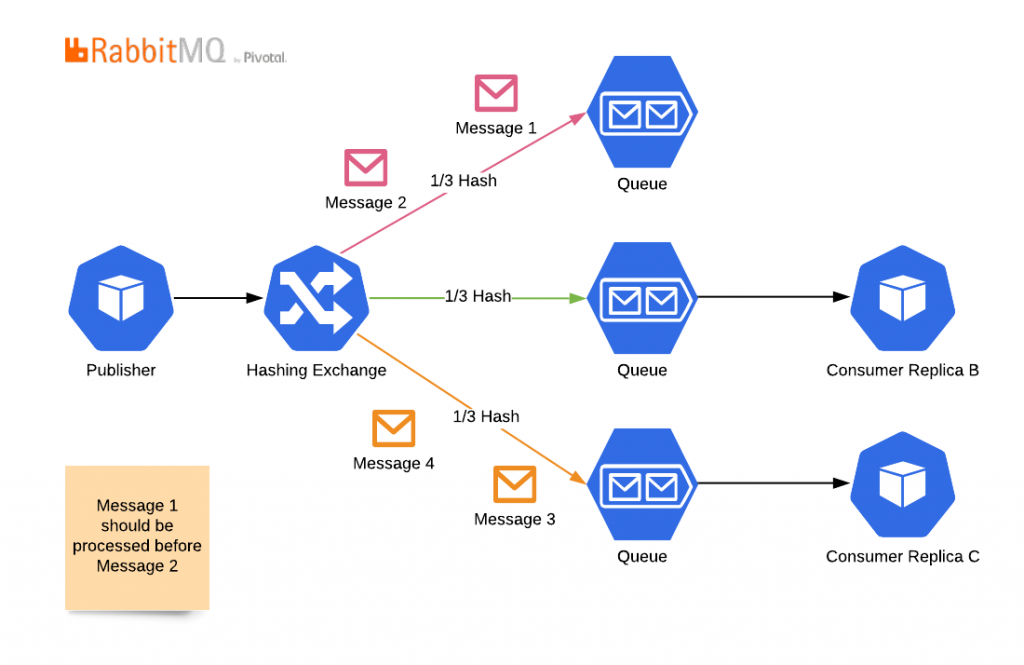
Anlık olarak karma algoritmalarını değiştirmeyecek, kuyrukları yeniden düzenlemeyecek ve tüketicileri atamayacaksınız; başlangıçta sahip olduğunuz tüketici sayısıyla sınırlı kalacaksınız. Bir tüketici birden fazla kuyruğa abone olabilse de, pratikte RabbitMQ bu abonelikleri yönetmek ve otomatik ölçeklendirme algoritmalarıyla senkronize etmek için kullanımı kolay bir çözüm sunmaz.
Kafka ise farklı bir yaklaşım kullanır. Aynı şekilde hashing kullanır ve RabbitMQ'da gördüğümüz Kuyruklara benzer Partisyonlara sahiptir. Mesajlar bir partisyon içinde sıralama garantilerine sahiptir, ancak partisyonlar arasında sıralama garantisi yoktur. Fark şu ki, Kafka abonelikleri kendisi yönetir. Bir partisyon yalnızca bir tüketiciye (bir tüketici grubunda, bir replika seti olarak düşünün) atanabilir. Eğer bir partisyonun tüketicisi yoksa, Kafka bir tüketici bulur ve ona atar.
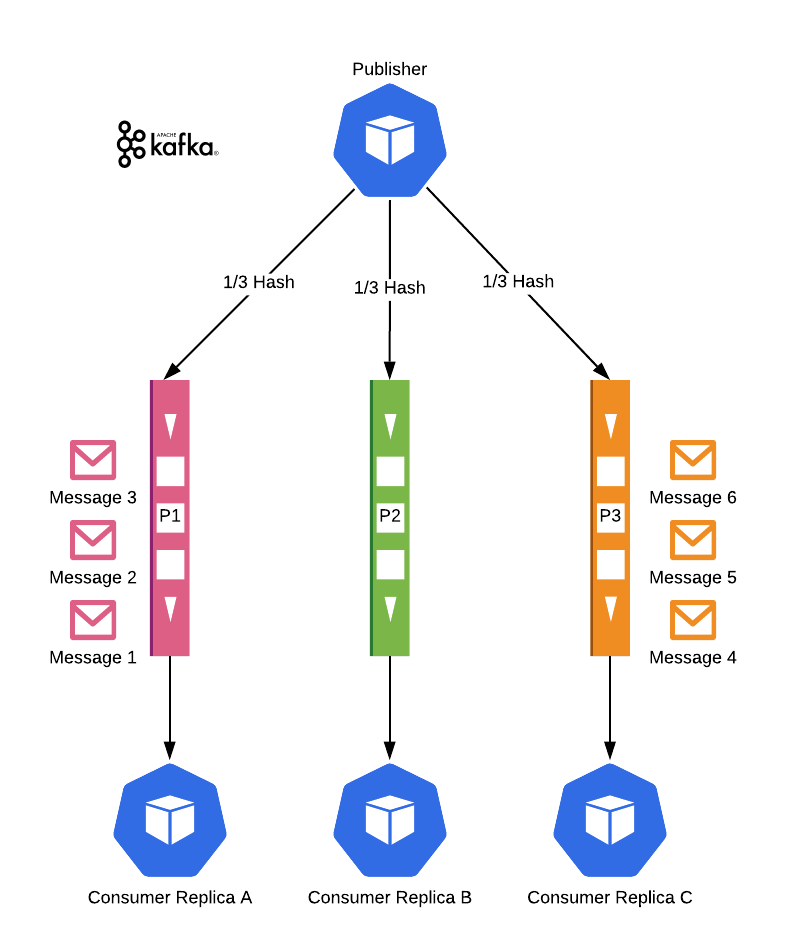
Bu nedenle, hashing algoritmalarımızın ilgili mesajları aynı Partition'a yerleştirmesi gerekir. Mesajlar arasında auto-scaling gerçekleşse bile, bunlar farklı servisler tarafından sırayla işlenecektir. Bu nedenle servisleri stateless tutmak esastır.
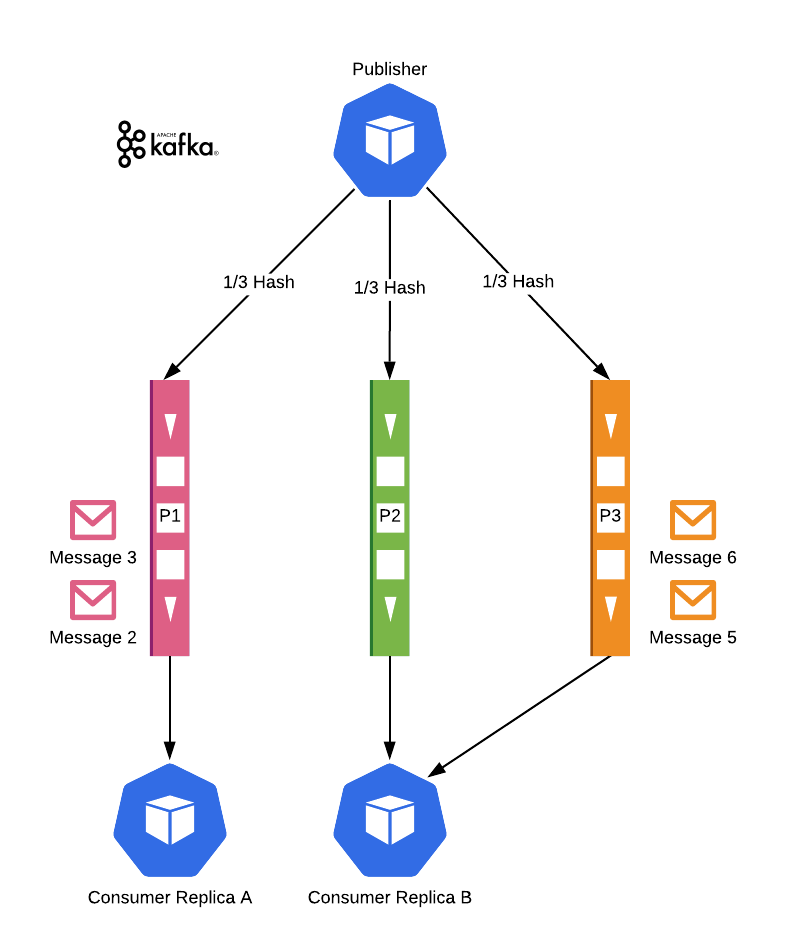
Kafka'nın farklı onay mekanizmaları vardır. Auto-ack, bir mesajın tüketiciye teslim edildiğinde işlendiği varsayılan bir mekanizmadır. Manual-ack ise tüketicinin mesajı işledikten sonra bir onay gönderdiği mekanizmadır. Manual-ack kullanarak, mesajların kaybolmadığından emin olabilir ve bu topolojinin çalışmasını sağlayabiliriz.Tabii ki, partisyon sayısı hala maksimum replika sayısını sınırlar. Fazla replikalar ise boşta bekler.
Elbette, bölüm sayısı yine de maksimum kopya sayısını sınırlar. Fazla kopyalar boşta kalır.
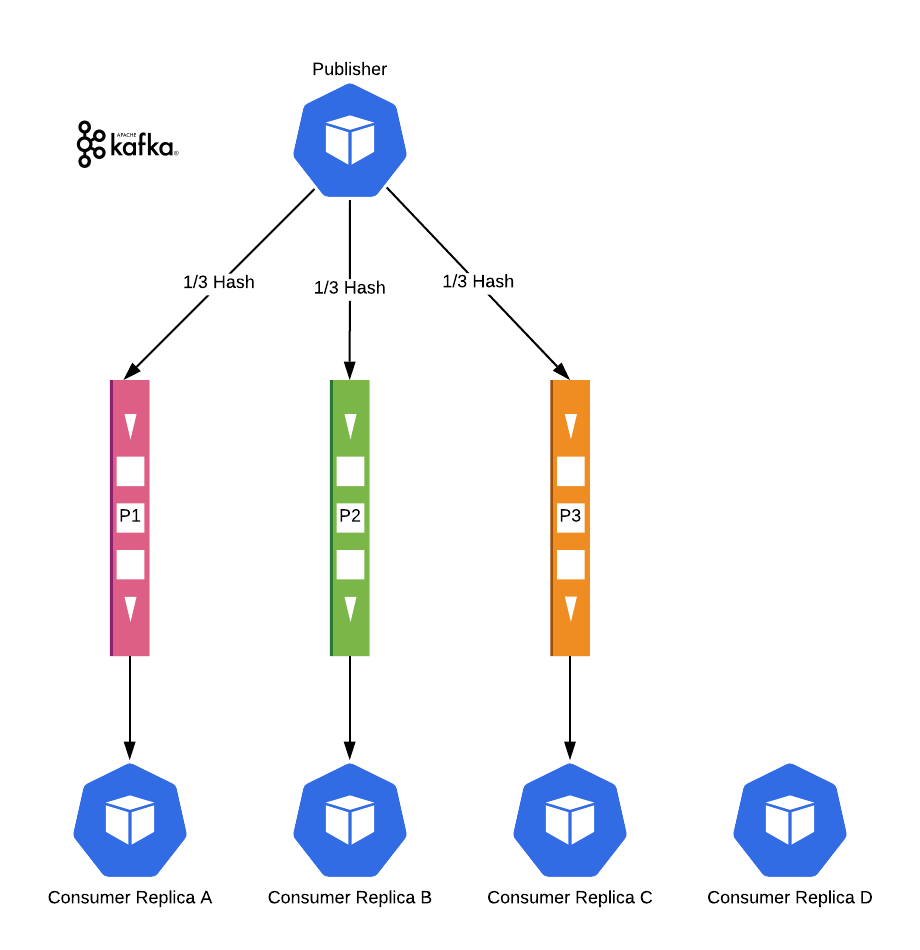
Ancak, yüksek sayıda partisyon belirleyerek auto-scaling’i kullanabilir ve message ordering’i de koruyabiliriz. Bu yüzden bizim durumumuzda Kafka kazandı.
Bu ana fark dışında Kafka'nın birkaç özelliğini daha beğendik. Birincisi, web soketi ve dağıtılmış izleme çözümlerimiz için güvendiğimiz günlük doğası. Organizasyonel olarak, insanlar bir mesajın RabbitMQ'da farklı kuyruklara kopyalanmasındansa tek bir kopyasına sahip olma fikrini daha çok sevdiler. Ayrıca, hala kullanmıyor olsak bile, event-sourcing bir altyapıya sahip olma seçeneği cazipti.
P.S.: Not: Biz bu kararları alırken Apache Pulsar henüz olgunlaşmamıştı.
Gecikmeli Çalıştırmalar
Biliyorsunuz, "ya şimdi yapmak istemezsem" durumu.
Kafka, gelecekteki işler için yerleşik desteğe sahip değildir. Şu andan itibaren x dakika sonra işlenecek bir mesaj gönderemezsiniz. Ancak bazen yapmanız gereken budur. Mesajı planlanan zamanda Kafka broker'ına gönderen ve ardından hemen işlenecek bir arka plan işleyicisine ihtiyacınız olacaktır.
Daha önce de belirttiğim gibi, üçüncü parti araçları mümkün olduğunca sınırlamaya çalışıyorduk ve gelişmiş zamanlama veya CRON Job özelliklerine ihtiyacımız yoktu. Dışarıdaki birçok mikro hizmet uygulaması gibi, ekosistemimizde zaten Redis vardı. Bu yüzden onu tercih ettik.
Redis'i zamanlanmış mesajlar için sorgulayan ve bunları önceden belirlenmiş hash anahtarıyla istenen Kafka konusuna ileten basit bir hizmetimiz var.
Mesajı, hedef konuyu, hash anahtarını ve teslim süresini içeren veri yapısına Envelope adını veriyoruz.
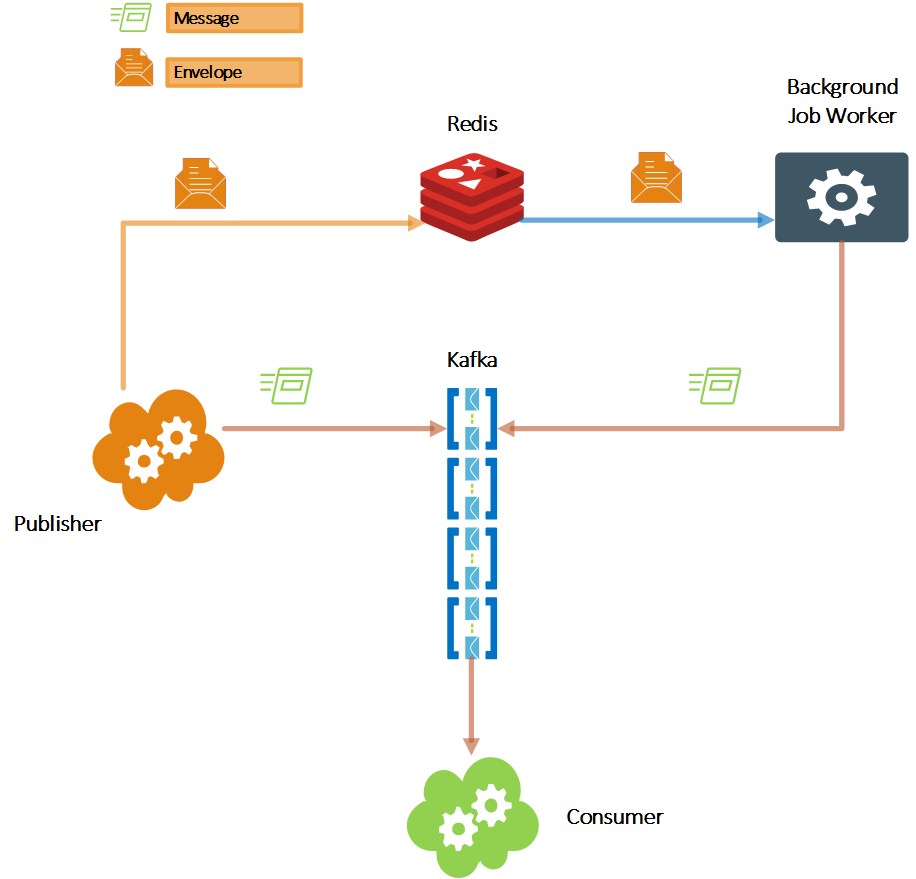
Yeterince iyi çalışıyor. Her halükarda, sistemin geri kalanından ayrılmıştır, bu nedenle daha gelişmiş sistemlere ihtiyacımız olursa, onu kolayca başka bir araçla değiştirebiliriz.
The critical thing to be aware of is that the Background Job Worker has the potential for being a single point of failure. Therefore it needs to be scaled too. So the first thing to consider is to use Redis transactions to prevent multiple executions of the same job by different worker instances. The second thing to consider is to not rely on it. Having multiple instances in a distributed environment is the ultimate recipe for things to go wrong. Therefore plan for idempotency. Just in case 🙂 We will talk about idempotency again.
Distributed Tracing
Oh, that age-old question; Who started the Mexican wave?
Devam etmeden önce, birkaç şeyden bahsetmek istiyorum. Kafka desteği olan bazı yetenekli dağıtık izleme araçları var. Bunları kullanmalısınız. Araştırın: Kafka Opentracing Instrumentation. Burada kimsenin ayağına basmaya çalışmıyoruz. Burada bahsedeceğim şey, tamamen kontrolümüzde olan ve başka olasılıklar açan ek, doğrudan bir çözümdür.
Mesaj dediğimiz şey, göndermek istediğimiz veriyi Yük (Payload) olarak içeren bir sarmalayıcı sınıftır. Altyapımız üzerinde diğer işlemleri gerçekleştirmek için kullandığımız ek özelliklere sahiptir. Kafka, gönderdiğiniz mesajlara bazı başlık değerleri ve özellikler ekler. Bu nedenle, karışıklığı önlemek için sınıfımızı PlatformMesaj olarak adlandıralım. PlatformMesaj şu şekilde genel bir sınıftır: PlatformMessage. PlatformMessage is a generic class as such;

Dağıtık izleme için birkaç ek bilgi tutarız. İş sürecini başlatan ilk istek bir RequestId ile yapılır. Bunu daha sonra ele alacağız. Ayrıca, her mesajın benzersiz bir kimliği vardır. İş süreci sırasında yeni bir mesaj oluşturmamız gerektiğinde, "CreateFollowUpMessage" yöntemini kullanırız. Bu yöntem, BreadCrumbs özniteliğini otomatik olarak doldurur. Tahmin edebileceğiniz gibi, BreadCrumbs özniteliği, geçmiş olayları sırayla izleyebilmemiz için sıralı mesaj metadatasının bir listesini tutar.
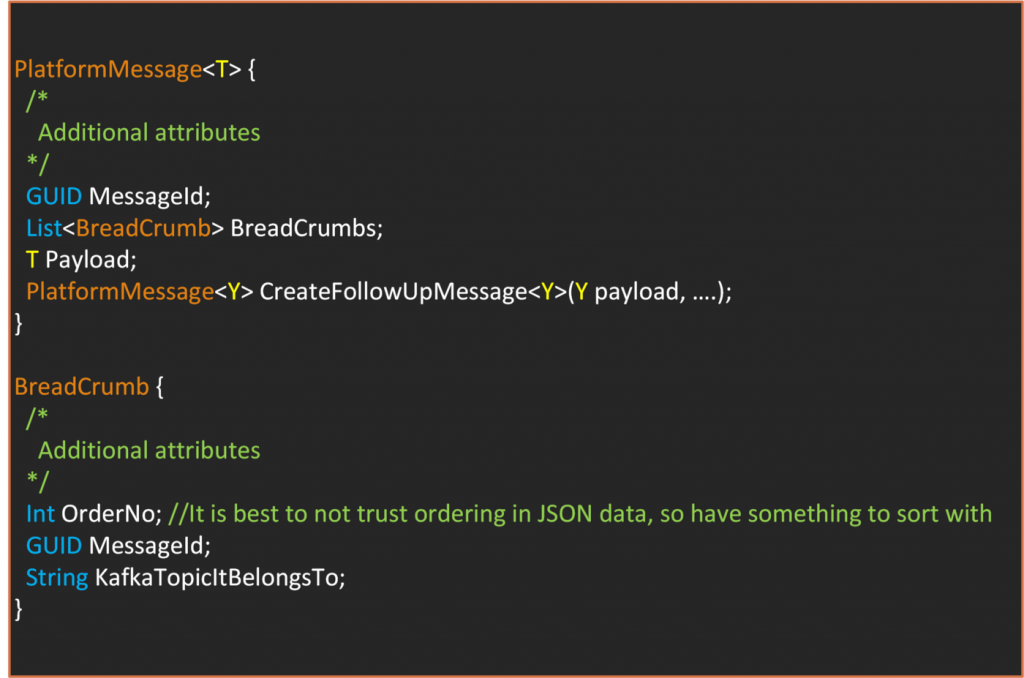
Bir mesajın içeriğine bakarak, hangi geçmiş olayların bu mesajın oluşturulmasına neden olduğunu anlayabilirsiniz. Bu, hata ayıklamada çok yardımcı olan basit bir çözümdür. Görünürdür, ek araçlara gerek duymaz ve daha sonra ele alacağımız diğer sorunları çözmeye yardımcı olur. Ancak, bazı eksiklikleri vardır. Aynı anda birden fazla mesajın üretildiği çatallanmaların tam bir resmini vermez. Sonraki mesajlar hakkında bilgi vermez. Performans metrikleri ekleyebilirsiniz, ancak bu muhtemelen gereğinden fazla olur ve özel bir izleme çözümü ile daha iyi yönetilmelidir.
Bu yüzden bu yaklaşımı üçüncü taraf bir izleme çözümüne ek bir özellik olarak öneriyoruz.